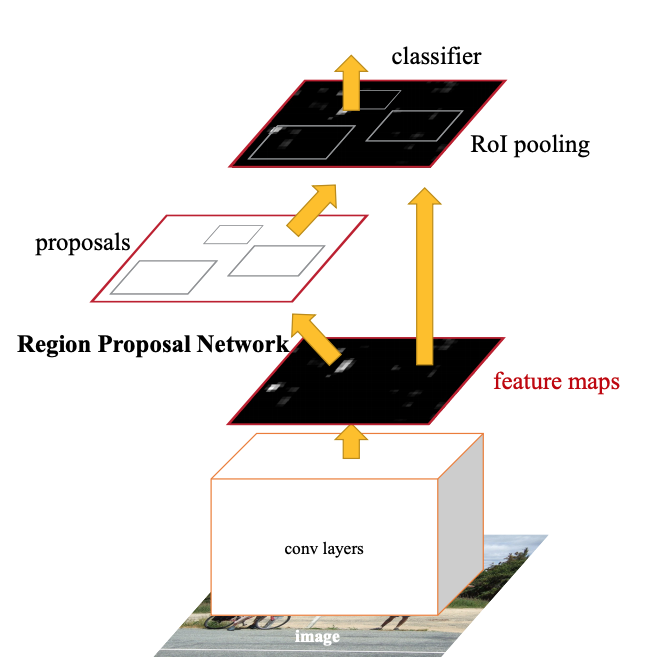
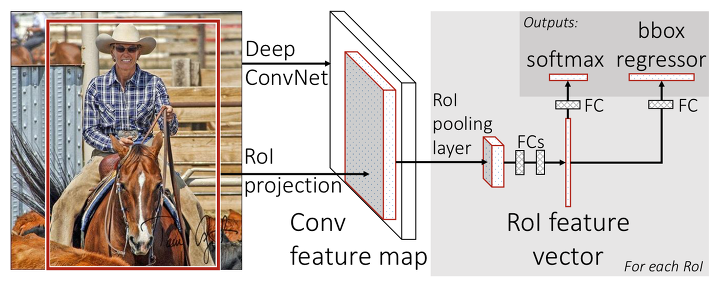
그림 1. Faster R-CNN 의 구조
Faster R-CNN 모델은 기존 딥러닝 기반의 객체검출 모델(R-CNN, Fast R-CNN)의 성능을 보완한 딥러닝 모델 입니다. Faster R-CNN 모델은 RPN 을 통해 선형 연산으로 빠르게 영역을 제안하기 때문에 실시간 영상 분석이 가능한 수준으로 Object Detection 분야를 이끌어 준 중요한 모델입니다.
구현된 코드는 https://github.com/kuiper68/implement-faster-rcnn/ 에서 확인할 수 있습니다. 코드는 Python, TensorFlow 를 사용하여 구현하였고 데이터 셋은 PASCAL VOC 2007 을 사용했습니다. 그러면 Faster-RCNN 의 리뷰를 시작하겠습니다.
Faster R-CNN은 크게 3개 의 Network 로 작동합니다. 이 세션에서는 각각의 역할을 소개하고 이를 구현합니다. 아래의 그림 1 에서 Faster R-CNN 모델의 구조를 살펴보겠습니다.
Faster R-CNN 모델에서 이미지를 입력받으면 Convolution 연산을 통해 어떤 정해진 크기 (H x W x D) 의 Feature-Map 을 출력합니다. 논문에서는 이 Feature-Map 추출 네트워크를 두 가지 제시 했습니다. 하나는 ZF 모델이고 다른 하나는 VGG-16 모델입니다. 이 모델들은 Classification 분야에서 영상의 특징을 추출하는데 사용됩니다. 그런데 Object Detection 에서는 똑같은 크기의 Feature-Map 을 활용하여 영상의 특징 뿐만 아니라 추가로 Regression 기법을 통해 Object 의 위치 정보도 출력합니다. 저는 이 부분을 VGG-16 모델을 사용하여 구현하였습니다. 이 네트워크 (Feature-Map Extractor) 는 그림 1 처럼 나머지 두 네트워크 (RPN, Detector) 에 연결됩니다.
다음은 RPN (Region Proposal Network) 입니다. 이 부분이 Faster R-CNN 의 가장 큰 특징이라 할 수 있습니다. 이전에 제시된 모델인 Fast R-CNN 에서는 RPN 대신 Selective-Search 알고리즘을 사용하여 영역을 제안했습니다. Selective-Search 는 영역 제안 속도가 RPN 에 비해 매우 (대략 14배 정도) 느린 CPU 기반의 알고리즘입니다. 반면 RPN 은 선형 연산을 활용한 모델이기 때문에 GPU 를 활용하여 빠른 영역 제안을 가능하게 만들어 주었습니다.
마지막 네트워크는 Detector 입니다. Detector 는 RPN 에서 제안 받은 영역을 일정한 사이즈의 Feature-Map 으로 Pooling 하여 Classification 과 Bounding-Box 도출에 활용합니다. 이 과정에서 Bounding-Box 의 Offset 을 조정하며 영역에 존재하는 Object 의 클래스를 예측합니다.
즉, Faster-RCNN 을 통해 Image Array 를 입력을 받을 때 연산 과정을 요약하면
그렇다면 아래 세부 세션에서 Faster-RCNN 모델의 각각의 네트워크에 대해 좀 더 자세히 설명해 보겠습니다.
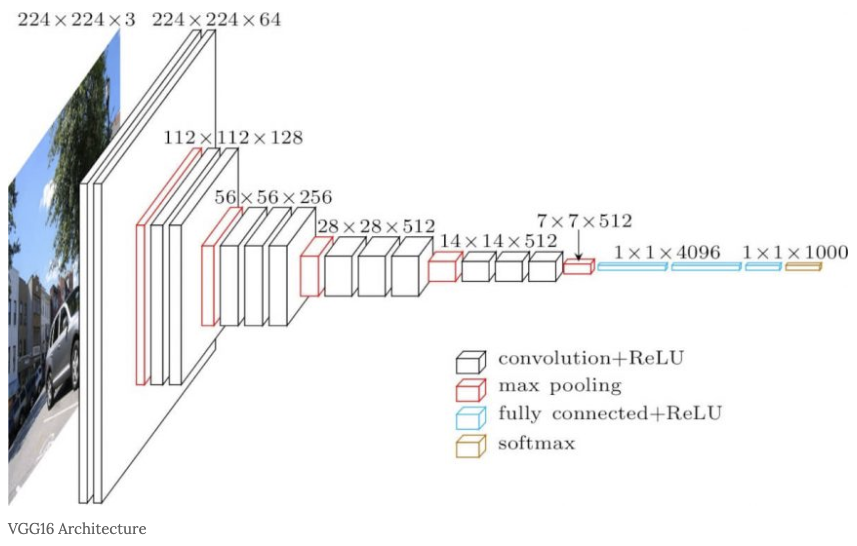
Feature Map Extractor 는 논문의 3.1 에서 제시한 방법대로 VGG-16 모델의 마지막 Layer 를 제외한 모든 Layer 들을 사용했습니다. 모델에 속한 Layer 들을 순차적으로 연산되어 Feature-Map 을 생성하게 됩니다. 이 과정은 Image/ Frame 을 Classification 하는 모델과 큰 차이가 없으며, 생성된 Feature-Map 은 RPN 이나 Detector 에 입력되어 학습 중 각각 네트워크의 파라미터를 업데이트 하게 될 것입니다.

RPN 은 Feature-Map Extractor 에서 생성된 Feature-Map 을 통해 어떤 Object의 존재 가능성과 Bounding-Box 위치를 출력합니다. 영역 제안의 수는 생성할 Anchor-Box 의 개수에 맞게 적용합니다. Anchor-Box 는 이미지상에서 Object 를 예측하기 위해 일정한 간격으로 나열된 일정한 넓이들을 가진 Bounding-Box 집합 입니다.
Anchor-Box 는 Area (넓이) 와 Aspect-Ratio (비율), 그리고 Stride (보폭) 을 설정하여 생성합니다. 저는 모든 이미지에 대해 일관성 있는 Anchor-Box 생성을 위해 논문에서 소개한 스타일대로 입력 이미지의 짧은 길이를 600 으로 이미지의 높이, 너비 비율을 같게하여 Rescale 한 뒤, Stride 는 입력 해상도와 출력될 Feature-Map 의 해상도의 비율을 고려하여 16 으로, 넓이는 [128 * 128, 256 * 256, 512 * 512] 그리고 비율은 [1:2, 1:1, 2:1] 로 설정하여 Anchor-Box 를 생성하였습니다. 따라서 구현 코드에서는 Anchor-Box 의 개수를 14 * 14 * 9 개로 설정 하여 이미지 경계를 신경쓰지 않고 전부 훈련했습니다.
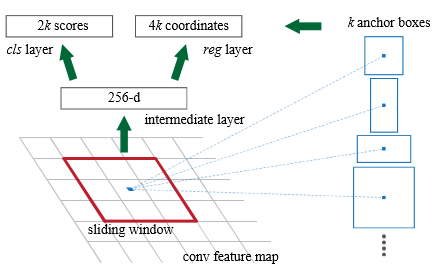
RPN 에서는 Feature-Map 을 통해 연산되어야 할 Output 의 크기를 1 X 1 Convolution 연산을 통해 조정합니다. 그림4와 같이 Feature-Map 은 Classification 과 Regression Layer 에 사용됩니다 (바로 두 문단 위에서 언급한 Object 의 존재 가능성, Bounding-Box 의 위치). Classification Layer 에서는 Object 가 존재하는지 (Positive, Negative) 를 예측해야 하기 때문에 RPN 의 최종 총 파라미터의 수는 그림 4 처럼 Bounding-Box 의 수 x 2 개가 있어야 하며, Regression Layer 는 생성된 Anchor-Box 를 통해 Encoding 좌표 값 (x, y, w, h) 을 계산하므로 Bounding-Box 의 수 X 4 개가 있어야 합니다. RPN 은 Object 가 존재하는 영역을 제안할 뿐이며 제안된 영역의 Object 의 클래스 예측은 다음에 나올 Detector 에서 하게 됩니다.
Detector 에서는 RoIPooling Layer 를 통해 Image/ Frame 상의 Object 의 크기에 상관없이 일정한 크기를 가지게 된 Feature-Map 들을 통해 영역의 Bounding-Box 와 Object 의 클래스를 예측하기 위해 사용됩니다. RoIPooling 단계에서 Feature-Map 을 활용한 예측 부분은 Fast R-CNN 과 같습니다. 또한 RPN 에서 제안한 영역에 대해 NMS (Non Maximum Suppression) 를 적용해서 중복된 제안 영역을 제거한 후 Object 가 존재할 가능성이 가장 높은 상위 n 개의 영역에 대해서만 RoIPooling 을 적용한다는 점을 주의하셔야 합니다.
Output 은 그림 5 와 같은 과정으로 도출됩니다. 최종 출력 Feature-Map 의 크기는 PASCAL-VOC 데이터 셋을 기준으로 한다면, Softmax (Classification) 에서는 최종 Feature-Map 의 수 X (20 + 1) (Object Class + Background) 개가 필요하며 BBox-Regression (Regression) 에서는 최종 Feature-Map 의 수 X (20 + 1) X 4 개가 필요합니다. 저는 Background 의 Bounding-Box 를 굳이 예측할 필요가 없지 않나 생각하여 BBox-Regression 의 파라미터를 최종 Feature-Map 의 수 X 20 X 4 개로 설정하였습니다.
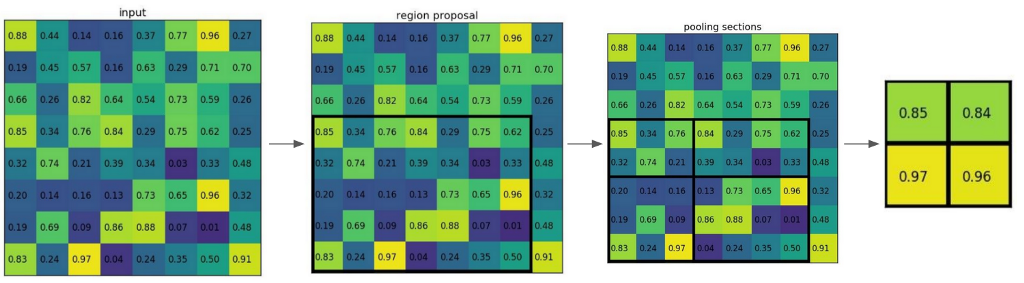
ROIPooling 은 Feature-Map Extractor 를 통해 획득한 Feature-Map 과 RPN 에서 제안된 영역을 활용하여 Feature-Map 상에서 제안된 영역들을 그림 6 과 같이 일정한 크기의 Feature-Map 으로 재구성하여 내보냅니다. RoIPooling 을 활용한 덕분에 크기가 다른 Feature-Map 에 대한 Classification 문제가 크기가 일정한 Feature-Map 에 대한 Classification 문제로 바뀌어서 간단하게 해결할 수 있었습니다.
지금까지는 Faster-RCNN 의 네트워크를 활용한 예측 과정에 대해 설명했습니다. 하지만 모델을 Training 할 경우 위에 작성된 내용만으로는 모호한 부분이 발생합니다. 저 또한 이 때문에 여러번 모델을 구현한 뒤 Training/ Testing 하는 작업에 많은 시간을 들였습니다. 그러면 다음 세션에서 Faster-RCNN 의 Training 과정을 살펴봅시다.
<annotation>
...
<filename>000005.jpg</filename>
...
<object>
<name>chair</name>
...
<bndbox>
<xmin>263</xmin>
<ymin>211</ymin>
<xmax>324</xmax>
<ymax>339</ymax>
</bndbox>
</object>
<object>
<name>chair</name>
...
<bndbox>
<xmin>165</xmin>
<ymin>264</ymin>
<xmax>253</xmax>
<ymax>372</ymax>
</bndbox>
</object>
...
<object>
...
</object>
</annotation>
Object Detection 모델에 활용되는 데이터는 기본적으로 Image Array, Bounding-Box 를 그리기 위한 직사각형의 네 변의 위치, 마지막으로 Object 의 클래스입니다. 제가 사용한 PASCAL-VOC 데이터 셋은 위와 같은 메타 데이터를 XML 로 제공하는 오픈 데이터 셋으로 Object Detection 모델을 Training 하기 위한 데이터가 포함되어 있습니다. 그러나 아직 Training 중 데이터의 처리과정을 설명하지 않았기 때문에 Faster R-CNN 을 완전히 이해하기 힘들 것 입니다. 우선 데이터 처리를 중심으로 논문에서 채택한 Training 과정인 4-step Alternating Training 을 소개하겠습니다.
4-step Alternating Training 이란 4단계의 과정을 통해 각각의 네트워크를 Training 한다는 의미입니다.
첫 번째 단계에서 Feature-Map Extractor 와 RPN 을 Training 하고, 두 번째 단계에서는 첫 번째 단계에서 Training 한 Feature-Map Extractor 와 RPN 을 통해 RoIPooling 과정에서 사용 될 Feature-Map 과 제안된 영역의 위치를 활용하여 Feature-Map Extractor 에서 Detector 에 이르는 파라미터 값을 업데이트 합니다. 이 때 RPN 은 Detector 를 업데이트 하기 위한 데이터 처리 (Generator 역할) 에 사용될 뿐 RPN 의 파라미터가 업데이트 되지는 않습니다.
세 번째와 네 번째 단계에서는 Feature-Map Extractor 네트워크의 파라미터를 Freezing (동결) 한 상태로 첫 번째, 두 번째 단계에서 처럼 각각 RPN 과 Detector 의 파라미터만 업데이트 합니다.
이러한 과정을 거치게 되면 3 개의 네트워크 (Feature-Map Extractor, RPN, Detector) 를 통해 Object Detection 이 가능해집니다.
그렇다면 Training 을 단계적으로 좀 더 자세히 설명해보겠습니다. 우선 첫 번째 단계에서 Feature-Map Extractor 와 RPN 을 Training 하기 위한 데이터 (입력-X 와 출력-Y) 가 필요합니다. 입력 값으로는 H x W x D 크기의 Image Array 를 사용합니다. 다음으로 출력 값을 생성할 차례입니다.
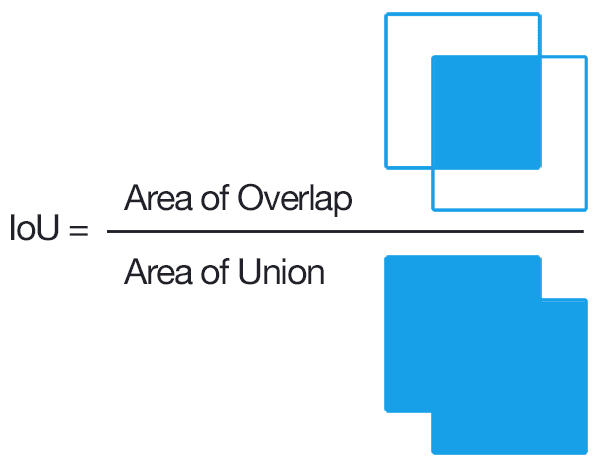
출력 값을 생성하기 위해 제일 먼저 할 일은 Anchor-Box 생성입니다. 저는 위에서 언급한 방법으로 Anchor-Box 를 생성하였습니다. 일정한 Stride 로 Image 상에 Anchor 를 생성했기 때문에 Ground-Truth 와 어느 정도 겹치는 Anchor 가 반드시 존재 (코드참고) 할 것 입니다. 그 겹치는 정도를 IoU (Intersection over Union) 라 불리는 0 에서 1 사이의 값으로 나타냅니다.
이 IoU 가 0.7 이상인 Anchor 에 대해서는 ‘Object 가 존재한다’ 하고 0.3 미만이면 ‘Object 가 존재하지 않는다’ 라고 정의합니다. 이외에 다른 Anchor 들은 RPN 의 Training 에 사용되지 않습니다.
하지만 이러한 기준으로는 Positive-Anchor (Object 가 존재하는) 의 수가 Negative-Anchor (Object 가 존재하지 않는) 의 수에 비해 압도적으로 부족합니다. 일반적으로 데이터 비율이 어느정도 맞아야만 재대로 된 Training 이 가능하기 때문에 Positive-Anchor 의 기준을 개선하여 개수를 더 늘려야 했습니다. 이를 위해 논문에서는 Anchor-Box 를 생성하게 되면 한 Point 당 Area 의 개수 x Aspect-Ratio 의 개수 만큼의 Anchor 가 생성되는 점을 활용하여 모든 Point 에 대해서 어떤 Point 에서 생성 된 Anchor 들 중 가장 큰 IoU 를 가지는 Anchor 의 IoU 가 0.3 이상이면 Positive-Anchor 에 포함시켰습니다. (코드참고)
Positive-Anchor 와 Negative-Anchor 를 구분했으면 다음은 영역에 Object 의 존재 유무를 Classification 하기 위해 두 집합 (Positive-Anchor 와 Negative-Anchor) 에서 Sampling 을 수행합니다. 일반적으로 Binary 데이터의 경우 1:1 비율로 구성하는 것이 좋습니다. 그러나 Positive-Anchor 의 기준을 개선하면서 까지 개수를 늘렸지만 여전히 Positive-Anchor 의 수가 부족하여 1:1 비율 설정이 불가능한 경우가 존재합니다. 이런 경우에는 하는 수 없이 Positive-Anchor 가 부족한 만큼 Negative-Anchor 를 Detector 에 제안해야 할 영역의 수에 맞게 늘려 Training 을 진행하였습니다. (코드참고)
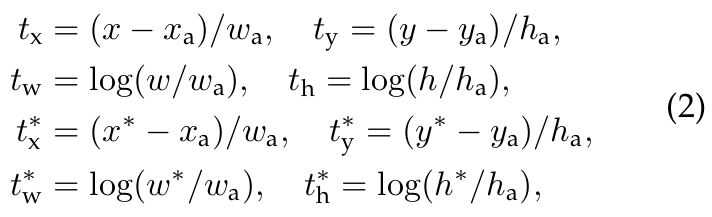
마지막으로 영역 제안을 위해 Ground-Truth 에 해당하는 위치 데이터 처리 과정을 살펴 보겠습니다. 위에서 예시로 든 XML 메타 데이터를 보면 Bounding-Box 에 해당하는 bndbox 태그가 있어서 xmin, ymin, xmax, ymax 로 Ground-Truth 를 표현하였습니다. 이것을 Center Coordinate 방식의 x*, y*, w*, h* 로 Encoding (변환) 합니다. (수식 1 에서 * 는 Ground-Truth, a 는 Anchor-Box, 아무 표시도 없는 것은 Prediction 을 나타냄)
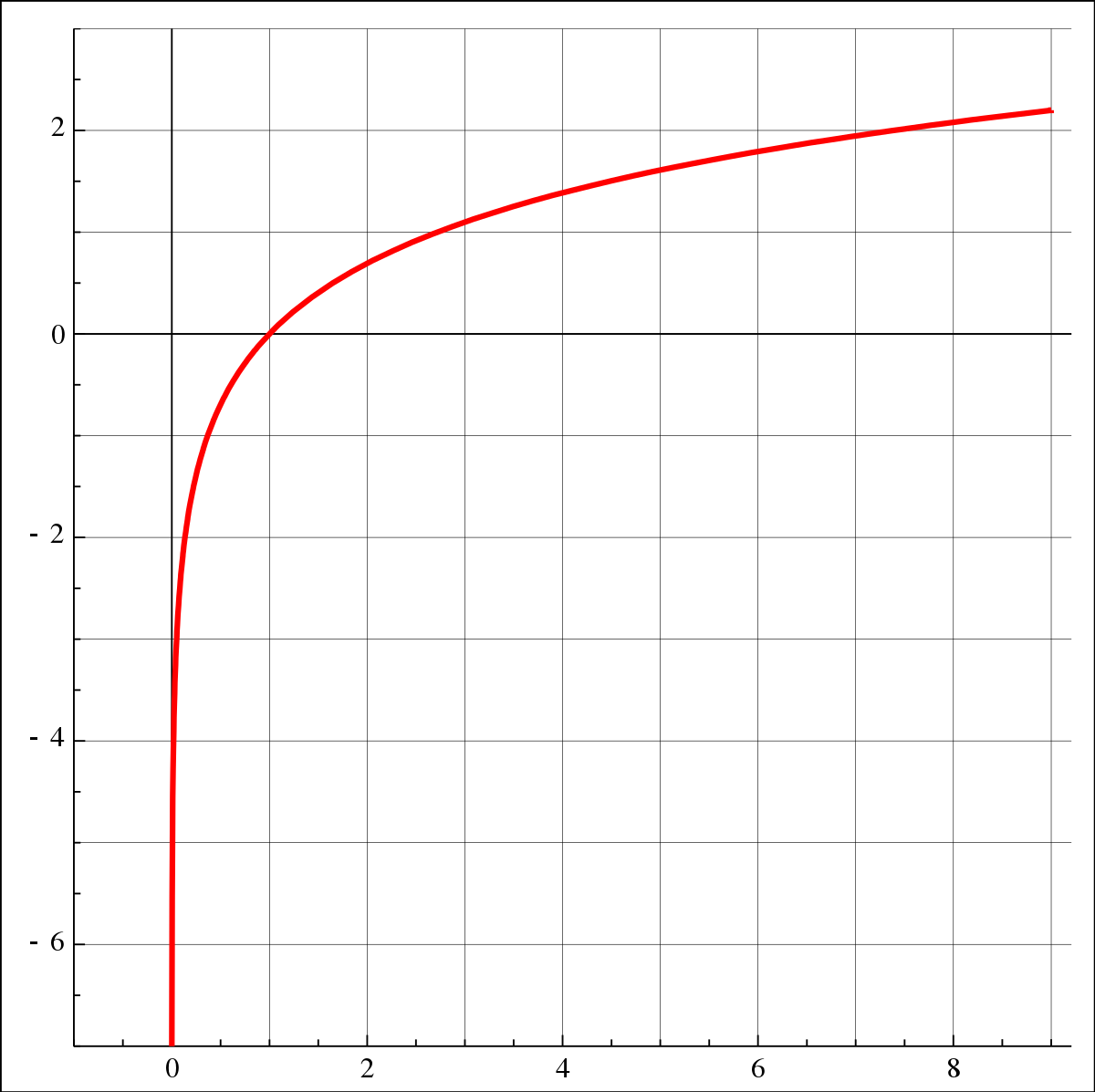
그리고 수식 1 에 의한 처리 과정을 통해 다시 한번 더 Encoding 됩니다. 여기서 Bounding-Box 의 크기를 결정짓는 w 와 h 에 대해서 log 함수를 사용했는데, 이유는 출력 값이 음수가 나와도 log 가 씌워진 값은 항상 양수일 수 밖에 없기 때문입니다. Bounding-Box 는 결국 직사각형 모양이기 때문에 모든 변은 양수 값을 가져야 하며 이를 위해 log 를 적절히 활용하여 Encoding 하였습니다. (코드참고)
즉, RPN 을 통해 발생하는 t_w, t_h 의 범위는 모든 실수이지만 Decoding 을 하게 되었을 때 log 함수는 w, h 의 범위를 양수로 제한할 수 있습니다.
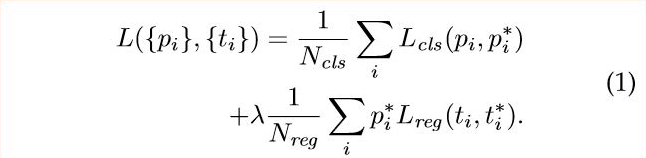
RPN 의 Training 은 Multi Task Loss 를 사용합니다. λ 는 Classification Loss 와 Regression Loss 의 균형을 잡기 위한 수식상의 매개변수이며 이 값을 10 으로 설정합니다. 그리고 Regression Loss 는 Object 가 존재하는 Anchor 에 대해서만 모델이 Training 할 수 있게 하기위해 p_i* 를 곱합니다.
Fast R-CNN 은 Feature-Map Extractor 와 Detector 를 연결한 모델과 같습니다. Fast R-CNN 에서는 Detector 를 통해 RPN 에서 제안한 Bounding-Box (RoI) 를 한번 더 조정하고 해당 영역에 존재하는 Object 의 클래스를 예측합니다.
즉, Detector 를 Training 하기 위해 Feature-Map Extractor 를 거쳐 나온 Feature-Map 과 RoI (RPN 을 통해 제안된 영역들) 가 입력 데이터 (X) 로, RoI 내에 존재하는 Object 의 클래스와 Ground-Truth 에 해당되는 Bounding-Box 를 출력 데이터 (Y) 로 활용해야 합니다.
하지만 4-step Alternating Training 의 두 번째 단계에서 ‘어떻게 Feature-Map Extractor 와 Detector 의 연산을 이어 함께 업데이트 할 수 있을까?’, 즉 두 네트워크 (Feature-Map Extractor, Detector) 의 파라미터 업데이트를 위해 역전파를 발생시키는 방법에 대한 궁금증이 발생할 것 입니다. Fast R-CNN 에서 설명하는 이론은 다음 수식 3 과 같습니다.
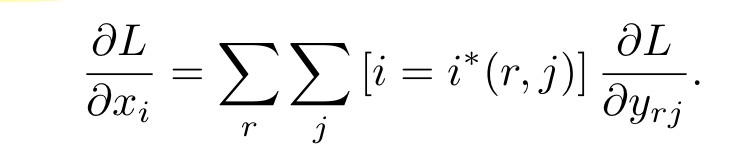
즉, Feature-Map Extractor 로 부터 생성된 Feature-Map 의 x_i (i 번째 Feature) 가 Detector 에 전달되려면 RoIPooling 으로부터 생성된 y_rj (r 번째 RoI 의 j 번째 Feature) 와 같은 값을 가져야 합니다. 따라서 Loss 를 y_rj 에 대해 편미분한 값을 모두 더하면 이는 결국 Loss 를 x_i 에 대해 편미분한 값과 같다는 의미입니다.
Detector 의 입력 값 중 RoI 에 대한 처리과정은 RPN 의 Training 을 이해했다면 충분히 구현 가능할 것 입니다. 출력 값의 처리 과정은 RPN 에서 활용했던 출력 값 처리 과정을 응용합니다. RPN 의 Object 존재 가능성을 예측하는 출력 (Binary Classification) 을 일반화 하여 Multi 클래스 예측에 활용하는 것 입니다. 그리고 Bounding-Box Regression 을 위한 데이터도 마찬가지로 Anchor-Box 대신 RPN 을 통해 출력된 Bounding-Box 를 활용하여 수식 1 을 통해 처리합니다. (코드참고)
다만 Object 가 존재하는 RoI (Positive) 와 Background 를 나타내는 RoI (Negative) 의 비율 처리에 대해 고민이 생기게 됩니다. 제가 구현한 코드 상에서 RPN 에서 처럼 0.7 을 Objcet 의 존재 Threshold (임계값) 으로 설정하면 Positive 인 Bounding-Box 의 수가 너무 적어져서 0.5 로 기준을 완화하였고 학습 시 Positive 와 Negative 의 비율은 Fast R-CNN 에서 설정한 1:3 을 적용하였습니다. (코드참고)
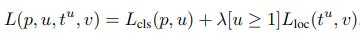
Loss 는 RPN 의 Training 의 Multi Task Loss 와 유사한 모델을 활용합니다. 클래스가 Background 인 RoI 에 대해서 Regression Layer 의 Training 을 막기위해 0을 곱하고 그렇지 않다면 1을 곱하며, 마찬가지로 λ 를 통해 Classification Loss 와 Regression Loss 의 균형을 보정합니다.
이것으로 Faster R-CNN 에 대한 리뷰를 마치겠습니다.
드디어 제 블로그에서 첫 번째 논문 리뷰가 끝났습니다. Faster R-CNN 을 구현한지 한참 지났는데 그 과정을 이렇게 문서로 요약하여 작성하는 것이 얼마나 어려운지 세삼 느낍니다. 열심히 작성했지만 다시 읽어보면 전달하고자 하는 의미가 스스로도 부족하게 느껴지기도 합니다. 하지만 ‘문서 작성도 계속 하다보면 언젠가 늘겠지’ 하는 마음으로 한 줄씩 작성해보고 부자연스러운 표현은 읽어보고 수정하며 첫 논문리뷰 작성을 마친 지금은 속으로 굉장히 뿌듯합니다.
Object Detection 분야의 실시간 분석에서 최근에는 Faster R-CNN 이후에 등장한 YOLO 라는 모델이 연산속도가 대략 6~7배 이상 훨씬 빠르며 더 정확한 모델이라는 점을 인지하고 있습니다. 하지만 Faster R-CNN 의 가장 큰 특징인 Anchor-Box 의 생성은 Object Detection 분야의 근본적인 뼈대가 되어 YOLO 모델을 업그레이드 하는데 사용되기도 했습니다. 그러한 점에서 Faster R-CNN 을 굉장히 가치있는 논문이라 판단하였고 실제로 저의 석사 연구에도 활용한적이 있습니다.
논문을 구현하면서 굉장히 아쉬운 점은 제가 논문에서 놓친 내용이 확인된 것과 Batch 처리 구현 기술입니다. 논문에서 생성하는 Anchor-Box 의 수는 Stride 를 작게 설정하여 대략 20,000 개인데 그 중에서 이미지의 경계를 넘어가는 것을 제외하여 약 6,000개 의 Anchor-Box 사용해 Training 하였는데 이 부분을 확인하지 못했고 RoIPooling 에서는 Batch 처리를 구현하지 못했습니다. 아마 이를 적용 한다면 제가 구현한 모델의 성능이 좀 더 좋아지고 Training 속도도 더욱 개선될 것으로 판단됩니다. 나중에 저도 레포지토리를 관리할 시간이 된다면 이 부분을 수정해 볼 예정입니다.
이상으로 글을 마칩니다. 제 리뷰가 잘 쓴 건지 모르겠지만 리뷰를 읽어주신 모든 분들께 감사드립니다.